목차-
1. 우분투 설치
2. 백엔드 프로그램 설치
3. 모델 구동및 웹서버 구현
1. 우분투 설치
Ubuntu 24.04LTS 영문으로 설치후
키보드 한글 추가
sudo systemctl enable --now ssh fail2ban unattended-upgrades
sudo ufw enable && sudo ufw allow 22/tcp && sudo ufw allow 8080/tcp
2. 백엔드 프로그램 설치
2-1. Nvidia 드라이버
우분투 기본 software & updates 에서 설치
Nvidia 그래픽카드 잡고
최신버전(숫자 높은거)
RTX 40시리즈 이상: NVIDIA Open Kernel (드라이버 555+) 기본 지원
RTX 30시리즈 이하: Closed Kernel 전용
골라서 설치

ubuntu-drivers devices
sudo ubuntu-drivers autoinstall # 또는 sudo apt install nvidia-driver-550
로도 가능합니다.
설치하고 나면 nvidia-smi로 확인해줍니다.
2-2. 쿠다툴킷 등
sudo apt update && sudo apt upgrade -y
sudo apt install -y build-essential cmake git curl wget software-properties-common

sudo apt install -y htop nvtop
전반적인거
글카만
이렇게 씁니다.
쿠다 툴킷을 필수적으로 설치해줍니다.
conda install -c nvidia cuda-toolkit
docker 기반 CUDA 이미지 사용 권장
bzip2 관련 오류 발생
sudo apt install -y build-essential cmake git curl wget software-properties-common
설치중에 bzip2 관련 설치진행 불가 내용이 떴습니다.
sudo apt install -y build-essential cmake git curl wget software-properties-common
Reading package lists... Done
Building dependency tree... Done Reading state information... Done
wget is already the newest version (1.21.4-1ubuntu4.1).
wget set to manually installed. software-properties-common is already the newest version (0.99.49.4).
software-properties-common set to manually installed.
Some packages could not be installed.
This may mean that you have requested an impossible situation or if you are using the unstable distribution that some required packages have not yet been created or been moved out of Incoming.
The following information may help to resolve the situation:
The following packages have unmet dependencies: dpkg-dev : Depends: bzip2 but it is not installable
E: Unable to correct problems, you have held broken packages.
이후 top3개는 깔려서 기본적인 거는 동작을 확인
apt 업데이트를 해도 정상입니다.
sudo apt --fix-broken install -y
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
깨진거도 없다네요.
sudo rm -rf /var/lib/apt/lists/*
sudo apt clean
sudo apt update && sudo apt upgrade -y
날리고 다시해줍니다.
lsb_release -a
sudo apt update
sudo apt install bzip2
cat /etc/apt/sources.list
차례대로 실행하며 bzip2 꼬인걸 풀어줍니다.
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
sudo software-properties-gtk
자동복구합니다.
bzip2 : Depends: libbz2-1.0 (= 1.0.8-5.1)
but 1.0.8-5.1build0.1 is to be installed
제 경우는 버전 불일치 문제입니다.
sudo apt install libbz2-1.0=1.0.8-5.1build0.1 bzip2=1.0.8-5.1build0.1
버전을 강제로 맞추거나
해결해줍니다.
sudo apt install -y build-essential cmake git curl wget software-properties-common
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
build-essential is already the newest version (12.10ubuntu1).
cmake is already the newest version (3.28.3-1build7).
git is already the newest version (1:2.43.0-1ubuntu7.3).
curl is already the newest version (8.5.0-2ubuntu10.9).
wget is already the newest version (1.21.4-1ubuntu4.1).
software-properties-common is already the newest version (0.99.49.4).
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
잘 설치되게 해줍니다.
2-3. 미니콘다 파이썬 가상화
이제 미니콘다로 파이썬 가상으로 분리해줍니다.
저는 파이썬으로 자동화를 시킬께 있어서 해줍니다.
그전에 확인차 쿠다 툴킷을 입력합니다.
sudo apt install -y nvidia-cuda-toolkit
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
nvidia-cuda-toolkit is already the newest version (12.0.140~12.0.1-4build4).
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
뜨면 파이썬을 설치합니다.
미니콘다 설치
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
~/miniconda3/bin/conda init bash
하단처럼 뜨면 터미널을 아예 종료후에 재시작해줍니다.
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
PREFIX=/home/ubunsv/miniconda3
Unpacking bootstrapper...
Unpacking payload...
Installing base environment...
Preparing transaction: ...working... done
Executing transaction: ...working... done
installation finished.
ubunsv@ubunsv-ROG-Strix-G731GW-G731GW:~$ ~/miniconda3/bin/conda init bash
no change /home/ubunsv/miniconda3/condabin/conda
no change /home/ubunsv/miniconda3/bin/conda
no change /home/ubunsv/miniconda3/bin/activate
no change /home/ubunsv/miniconda3/bin/deactivate
no change /home/ubunsv/miniconda3/etc/profile.d/conda.sh
no change /home/ubunsv/miniconda3/etc/fish/conf.d/conda.fish
no change /home/ubunsv/miniconda3/shell/condabin/Conda.psm1
no change /home/ubunsv/miniconda3/shell/condabin/conda-hook.ps1
no change /home/ubunsv/miniconda3/lib/python3.13/site-packages/xontrib/conda.xsh
no change /home/ubunsv/miniconda3/etc/profile.d/conda.csh
modified /home/ubunsv/.bashrc
==> For changes to take effect, close and re-open your current shell. <==
재시작후에는

이렇게 (base)로 뜨면 맞게 된겁니다.
콘다를
conda config --set channel_priority strict
conda create -n llm python=3.10 -y

이렇게 설치가 진행되면서

이렇게 llm으로 base에서 바뀝니다.
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
sudo usermod -aG docker $USER
이제 도커를 깔아줍니다.
재부팅 권장
이후
콘다 액티브
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
로 gpu를 도커에 붙여서 쓸수있게 해줍니다.
이제 확인을 해줍니다.
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
docker run --rm --gpus all ubuntu nvidia-smi

위 이미지 처럼 잘 인식되면 성공입니다.
이제 Llam.cpp를 설치해줍니다.
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
# 1. 가상환경 접속 (이미 되어있다면 생략)
conda activate llm
# 2. 기존 빌드 폴더 찌꺼기 삭제 (꼬임 방지)
rm -rf build
# 3. Conda 안의 CUDA 컴파일러(nvcc)를 사용하도록 지정하며 빌드
CUDACXX=$CONDA_PREFIX/bin/nvcc cmake -B build -DGGML_CUDA=ON -DLLAMA_CURL=ON
# 여기서
CMake Error at /usr/share/cmake-3.28/Modules/CMakeTestCCompiler.cmake:67 (message):
The C compiler
"/usr/bin/cc"
is not able to compile a simple test program.
같은 에러가 난다면
Conda 가상환경의 구형 링커(ld)가 우분투 24.04 시스템과 충돌해서 생기는 문제입니다.
따라서 Conda 안의 ld 파일 이름을 살짝 바꿔서 무효화하고,
우분투 본연의 최신 링커를 쓰도록 강제해 주면 해결됩니다.
mv $CONDA_PREFIX/bin/ld $CONDA_PREFIX/bin/ld_backup
하고나서
rm -rf build
CUDACXX=$CONDA_PREFIX/bin/nvcc cmake -B build -DGGML_CUDA=ON -DLLAMA_CURL=ON
#4. 링커에게 Conda 라이브러리 경로를 고정
export LIBRARY_PATH=$CONDA_PREFIX/lib:$LIBRARY_PATH
실행때도 Conda 라이브러리 경로를 고정
export LD_LIBRARY_PATH=$CONDA_PREFIX/lib:$LD_LIBRARY_PATH
# 5. 컴파일 진행
cmake --build build --config Release -j 6
# 전체빌드
아니면
cmake --build build --config Release -j 6 --target llama-server llama-bench
# 서빙이랑 벤치만 빌드
차례로 하면
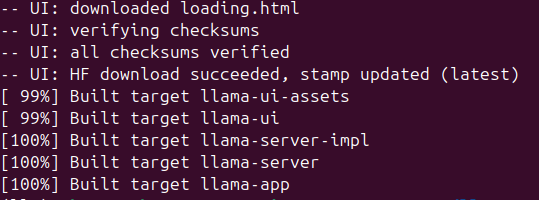
빌드가 끝납니다.
인데 I7-9750H 라서 6이고 본인의 물리 프로세서 수 입력하시면 됩니다.

3. 모델 구동및 웹서버 구현
sudo apt install -y libssl-dev libcurl4-openssl-dev
sudo apt update && sudo apt upgrade -y
이후
본인이 사용할 모델 선택
저는 unsloth팀이 양자화한 qwen3.6-27b 골랐습니다. Mtp로요.
unsloth/Qwen3.6-27B-MTP-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
cmake -B build -DGGML_CUDA=ON -DLLAMA_CURL=ON -DLLAMA_OPENSSL=ON
cmake --build build --config Release -j 6
인터넷에서 받아서 실행하는 기능 추가하고 다시 빌드해줍니다.
./build/bin/llama-server -hf unsloth/Qwen3.6-27B-MTP-GGUF:UD-Q8_K_XL -ngl 4 -c 8192 -t 6 -fa --port 8080
이렇게 하면
unsloth # unsloth팀의
/
Qwen3.6-27B-MTP-GGUF # Qwen3.6-27B의 MTP추가된 GGUF 포맷 모델을
:UD-Q8_K_XL # 8비트 큰 양자화(사이즈가 큽니다)
-ngl 4 -c 8192 -t 6 -fa on --port 8080 # 4개층을 gpu로 8192컨택스트에 cpu6코어에 플래쉬 어탠션 켜고
입니다.
따라서 본인의 컴퓨터에 맞춰서 실행해주세요.
벤치 명령어
./build/bin/llama-bench -hf unsloth/Qwen3.6-27B-MTP-GGUF:UD-Q8_K_XL -ngl 4 -t 6 -p 1024 -n 128

벤치결과 이렇게 나오네요.
현실적으로 쓰긴 힘든 속도구요.
에이전트로 일 던져놓거나,
호기심?등으로는 해볼만 합니다.
M4-48렘
qwopus-MTP 벤치도 첨부합니다.


실사용중 데이터입니다.
qwen순정이랑은 조금 차이가 납니다.
MTP켜기도 했고 RAG도 있고 프롬프트도 좀 길고 qwopus라서 조금 다를수도 있습니다.
도커 세팅은 향후 컨테이너 환경의 AI 툴킷(vLLM, Ollama 등)을 쓸 때를 대비한 사전 작업이고,
이번 포스팅에서는 직접 로컬 빌드 방식 테스트 구동합니다
'LLM' 카테고리의 다른 글
| 경험삼아 mlx기반 QLoRA 해보기-2부 (0) | 2025.11.07 |
|---|---|
| 경험삼아 mlx기반 QLoRA 해보기-1부 (0) | 2025.11.07 |
| DeepSeek 깔아보기 (0) | 2025.01.29 |
| PHI4써보기 (0) | 2025.01.15 |